Kā instalēt un iestatīt Apache Spark Ubuntu/Debian
Apache Spark ir atvērtā koda izplatīts skaitļošanas ietvars, kas izveidots, lai nodrošinātu ātrākus skaitļošanas rezultātus. Tas ir atmiņā iebūvēts skaitļošanas dzinējs, kas nozīmē, ka dati tiks apstrādāti atmiņā.
Spark atbalsta dažādas API straumēšanai, grafiku apstrādei, SQL, MLLib. Tas arī atbalsta Java, Python, Scala un R kā vēlamās valodas. Spark galvenokārt tiek instalēts Hadoop klasteros, taču varat arī instalēt un konfigurēt Spark savrupajā režīmā.
Šajā rakstā mēs redzēsim, kā instalēt Apache Spark izplatījumos, kuru pamatā ir Debian un Ubuntu.
Instalējiet Java un Scala Ubuntu
Lai Ubuntu instalētu Apache Spark, jūsu datorā ir jābūt instalētai Java un Scala. Lielākajai daļai mūsdienu izplatījumu pēc noklusējuma ir instalēta Java, un to varat pārbaudīt, izmantojot šo komandu.
$ java -version

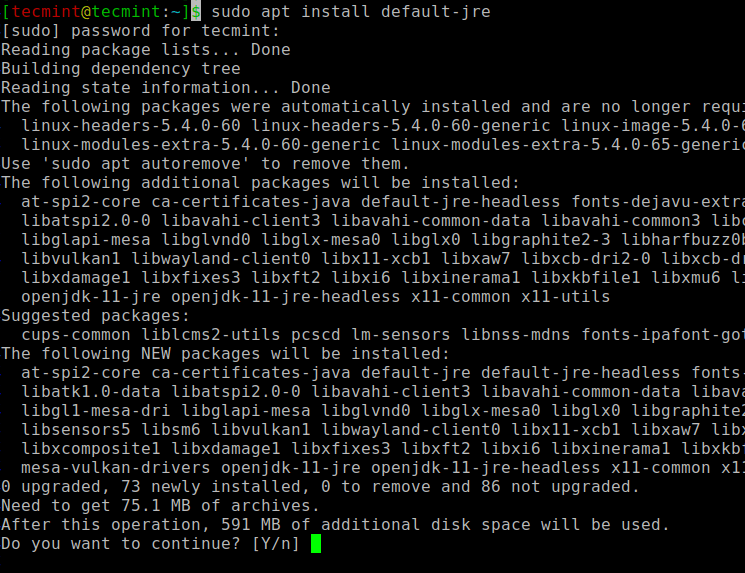
Ja nav izvades, varat instalēt Java, izmantojot mūsu rakstu par Java instalēšanu Ubuntu vai vienkārši palaidiet šādas komandas, lai instalētu Java Ubuntu un Debian izplatījumos.
$ sudo apt update $ sudo apt install default-jre $ java -version
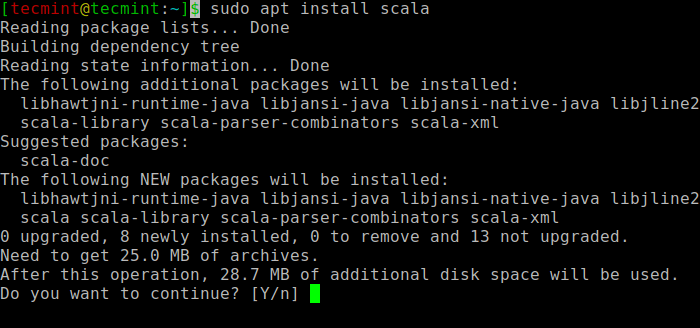
Pēc tam varat instalēt Scala no apt repozitorija, izpildot šādas komandas, lai meklētu scala un instalētu to.
$ sudo apt search scala ⇒ Search for the package $ sudo apt install scala ⇒ Install the package
Lai pārbaudītu Scala instalēšanu, palaidiet šo komandu.
$ scala -version Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Instalējiet Apache Spark Ubuntu
Tagad dodieties uz oficiālo komandu wget, lai lejupielādētu failu tieši terminālī.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
Tagad atveriet savu termināli un pārslēdzieties uz vietu, kur atrodas lejupielādētais fails, un palaidiet šo komandu, lai izvilktu Apache Spark tar failu.
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz
Visbeidzot, pārvietojiet izvilkto Spark direktoriju uz /opt direktoriju.
$ sudo mv spark-3.1.1-bin-hadoop2.7 /opt/spark
Konfigurējiet Spark vides mainīgos
Tagad pirms dzirksteles palaišanas .profile failā ir jāiestata daži vides mainīgie.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile $ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile $ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
Lai nodrošinātu, ka šie jaunie vides mainīgie ir sasniedzami čaulā un pieejami Apache Spark, ir arī obligāti jāpalaiž šī komanda, lai stātos spēkā nesenās izmaiņas.
$ source ~/.profile
Visi ar dzirksteli saistītie binārie faili, lai sāktu un apturētu pakalpojumus, atrodas mapē sbin.
$ ls -l /opt/spark

Sāciet Apache Spark Ubuntu
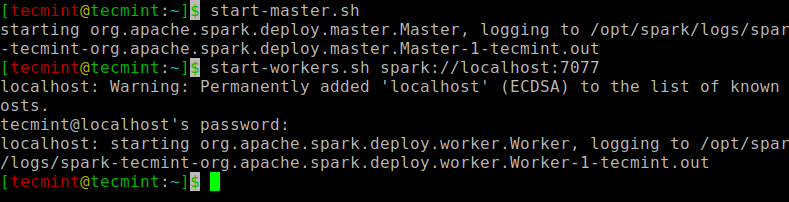
Palaidiet šo komandu, lai palaistu Spark galveno pakalpojumu un pakārtoto pakalpojumu.
$ start-master.sh $ start-workers.sh spark://localhost:7077
Kad pakalpojums ir palaists, dodieties uz pārlūkprogrammu un ierakstiet šo URL piekļuves dzirksteļa lapu. No lapas jūs varat redzēt, ka mans saimnieka un vergu pakalpojums ir sākts.
http://localhost:8080/ OR http://127.0.0.1:8080

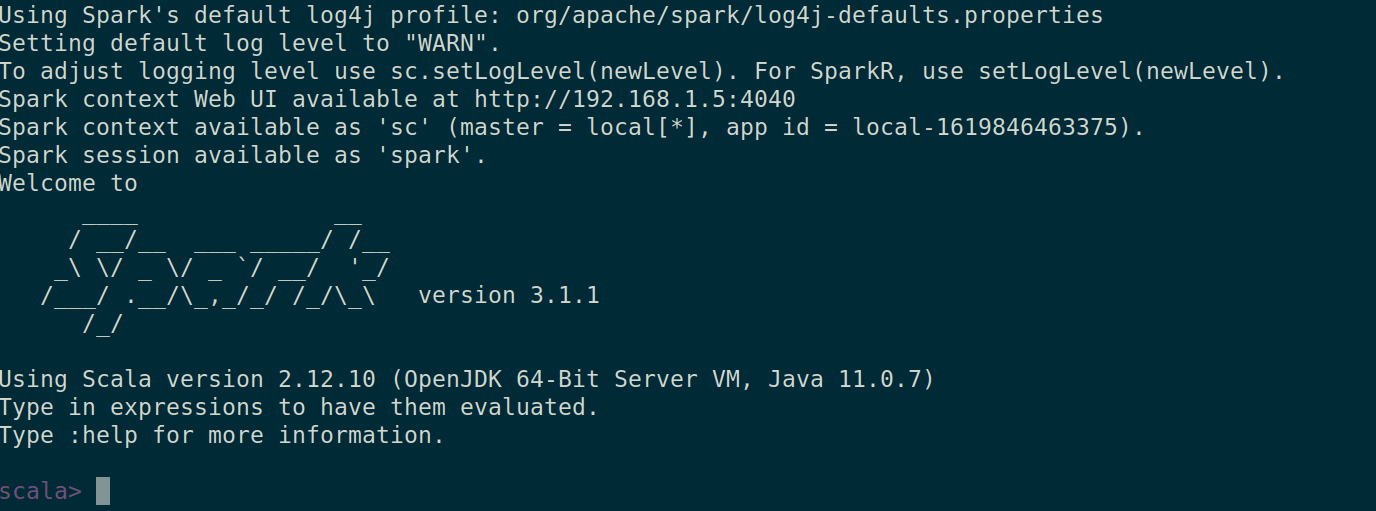
Varat arī pārbaudīt, vai spark-shell darbojas labi, palaižot spark-shell komandu.
$ spark-shell
Tas ir viss šim rakstam. Pavisam drīz mēs jūs pieķersim ar vēl vienu interesantu rakstu.