20 noderīgi egrep komandu piemēri operētājsistēmā Linux
Īsumā: šajā rokasgrāmatā mēs apspriedīsim dažus komandas egrep praktiskos piemērus. Pēc šīs rokasgrāmatas izpildes lietotāji varēs efektīvāk veikt teksta meklēšanu operētājsistēmā Linux.
Vai esat kādreiz bijis neapmierināts, jo nevarat žurnālos atrast nepieciešamo informāciju? Nepieciešamās informācijas iegūšana no lielas datu kopas ir sarežģīts un laikietilpīgs uzdevums.
Lietas kļūst patiešām sarežģītas, ja operētājsistēma nenodrošina pareizos rīkus un šeit nāk Linux, lai jūs glābtu. Linux nodrošina dažādas teksta filtrēšanas utilītas, piemēram, sed, cut utt.
Tomēr egrep ir viena no jaudīgākajām un visbiežāk izmantotajām utilītprogrammām teksta apstrādei operētājsistēmā Linux, un mēs apspriedīsim dažus komandas egrep piemērus.
Egrep komandu operētājsistēmā Linux atpazīst grep komandas saime, kas tiek izmantota, lai meklētu un saskaņotu noteiktu paraugu failos. Tas darbojas līdzīgi kā grep -E (grep Extended regex), taču tas galvenokārt meklē noteiktu failu vai pat rindas uz rindu vai izdrukā rindiņu dotajā failā.
Komandas egrep sintakse ir šāda:
$ egrep [OPTIONS] PATTERNS [FILES]
Lai izmantotu piemēru, izveidosim teksta faila paraugu ar šādu saturu:
$ cat sample.txt

Šeit mēs redzam, ka teksta fails ir gatavs. Tagad apspriedīsim dažus izplatītus piemērus, kurus var izmantot ikdienā.
Sāksim ar vienkāršu parauga atbilstības piemēru, kur mēs varam izmantot tālāk norādīto komandu, lai failā sample.txt meklētu virkni professional:
$ egrep professionals sample.txt

Šeit mēs redzam, ka komanda izdrukā rindu, kurā ir norādītais modelis.
Mēs varam padarīt izvadi informatīvāku, izceļot atbilstošo modeli. Lai to panāktu, mēs varam izmantot komandas egrep opciju --color. Piemēram, tālāk norādītā komanda sarkanā krāsā iezīmēs tekstu profesionāļi:
$ egrep --color=auto professionals sample.txt

Šeit mēs redzam, ka tā pati izvade ir informatīvāka salīdzinājumā ar iepriekšējo. Turklāt mēs varam viegli noteikt, ka vārds profesionāļi tiek atkārtots divas reizes.
Lielākajā daļā Linux sistēmu iepriekš minētais iestatījums ir iespējots pēc noklusējuma, izmantojot šādu aizstājvārdu:
$ alias egrep='egrep –color=auto'
Komanda egrep pieņem vairākus failus kā argumentu, kas ļauj mums meklēt noteiktu modeli vairākos failos. Sapratīsim to ar piemēru.
Vispirms izveidojiet faila sample.txt kopiju:
$ cp sample.txt sample-copy.txt
Tagad abos failos meklējiet modeli profesionāļi:
$ egrep professionals sample.txt sample-copy.txt

Iepriekš minētajā piemērā mēs varam redzēt faila nosaukumu izvadē, kas apzīmē atbilstošo rindiņu no šī faila.
Dažreiz mums vienkārši jānoskaidro, vai failā ir vai nav raksts. Ja jā, tad cik rindās tā ir? Šādos gadījumos mēs varam izmantot komandas opciju -c.
Piemēram, tālāk esošā komanda kā izvadi parādīs 1, jo vārds profesionāļi ir tikai vienā rindā.
$ egrep -c professionals sample.txt 1
Iepriekšējā piemērā mēs redzējām, ka opcija -c neuzskaita modeļa gadījumu skaitu. Piemēram, vārds profesionāļi tiek parādīts divas reizes vienā rindā, bet opcija -c to uzskata tikai par vienu atbilstību.
Šādos gadījumos mēs varam izmantot komandas opciju -o, lai drukātu tikai atbilstošo modeli. Piemēram, tālāk esošā komanda rādīs vārdu profesionāļi divās atsevišķās rindās:
$ egrep -o professionals sample.txt
Tagad saskaitīsim rindas, izmantojot komandu wc:
$ egrep -o professionals sample.txt | wc -l

Iepriekš minētajā piemērā mēs esam izmantojuši egrep un wc komandu kombināciju, lai saskaitītu konkrētā modeļa gadījumu skaitu.
Pēc noklusējuma egrep veic raksta saskaņošanu reģistrjutīgā veidā. Tas nozīmē vārdus – mēs, Mēs, MĒS un MĒS tiek traktēti kā dažādi vārdi. Tomēr mēs varam ieviest meklēšanu bez reģistrjutīga, izmantojot opciju -i.
Piemēram, tālāk norādītajā komandu paraugā tiks nodrošināta atbilstība tekstam mēs un Mēs:
$ egrep -i we sample.txt

Iepriekšējā piemērā mēs redzējām, ka komanda egrep veic daļēju atbilstību. Piemēram, kad mēs meklējām tekstu mēs, modeļa atbilstība izdevās arī citiem tekstiem. Piemēram, tīmeklis, vietne un bija.
Lai pārvarētu šo ierobežojumu, mēs varam izmantot opciju -w, kas nodrošina visu vārdu atbilstību.
$ egrep -w we sample.txt

Līdz šim mēs izmantojām komandu egrep, lai izdrukātu rindas, kurās atrodas dotais raksts. Tomēr dažreiz mēs vēlamies veikt operāciju pretējā veidā.
Piemēram, mēs varam vēlēties izdrukāt rindas, kurās nav norādītā raksta. Mēs to varam panākt, izmantojot -v opciju:
$ egrep -v we sample.txt

Šeit mēs redzam, ka komanda izdrukā visu rindiņu, kurā nav teksta mēs.
Mēs varam izmantot komandas opciju -n, lai iespējotu rindu numerāciju, kas parāda rindas numuru izvadē, kad modeļa atbilstība ir veiksmīga. Šis vienkāršais triks padara rezultātu jēgpilnāku.
$ egrep -n professionals sample.txt

Iepriekš redzamajā izvadē mēs varam redzēt, ka vārds profesionāļi atrodas 5. rindā.
Klusajā režīmā komanda egrep nedrukā atbilstošo modeli. Tāpēc mums ir jāizmanto komandas atgriešanas vērtība, lai noteiktu, vai modeļa atbilstība ir veiksmīga.
Mēs varam izmantot komandas opciju -q, lai iespējotu kluso režīmu, kas noder, rakstot čaulas skriptus.
$ egrep -q professionals sample.txt $ egrep -q non-existing-pattern sample.txt

Šajā piemērā nulles atgriešanas vērtība norāda uz modeļa esamību, savukārt vērtība, kas nav nulle, norāda uz modeļa neesamību.
Dažreiz ir lietderīgi parādīt dažas līnijas ap atbilstošo modeli. Šādos gadījumos mēs varam izmantot komandas opciju -B, kas parāda N rindiņas pirms atbilstošā modeļa.
Piemēram, tālāk norādītā komanda izdrukās rindiņu, kurai izdodas parauga atbilstība, kā arī 2 rindas pirms tās.
$ egrep -B 2 -n professionals sample.txt

Šajā piemērā mēs esam izmantojuši opciju -n, lai parādītu rindu numurus.
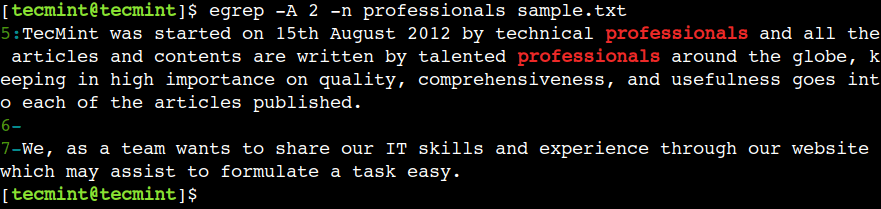
Līdzīgā veidā mēs varam izmantot komandas opciju -A, lai parādītu rindas pēc modeļa atbilstības. Piemēram, tālāk norādītā komanda izdrukās rindiņu, kurai izdodas parauga atbilstība, kā arī nākamās 2 rindas.
$ egrep -A 2 -n professionals sample.txt
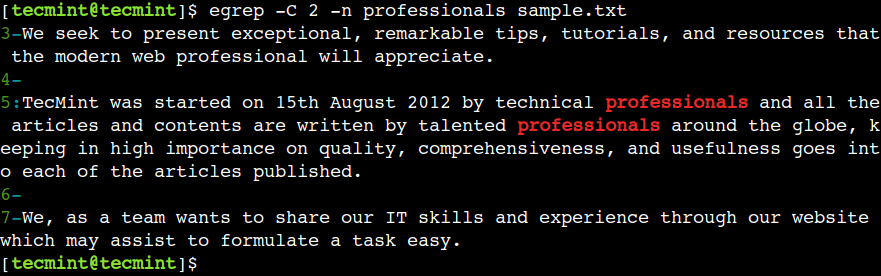
Papildus tam komanda egrep atbalsta opciju -C, kas apvieno opciju -A un -B funkcionalitāti, kas parāda līnijas pirms un pēc saskaņotā raksta.
$ egrep -C 2 -n professionals sample.txt
Kā minēts iepriekš, mēs varam veikt modeļu saskaņošanu vairākiem failiem. Tomēr situācija kļūst sarežģīta, ja faili atrodas vairākos apakšdirektorijos un mēs tos visus nododam kā komandu argumentus.
Šādos gadījumos mēs varam veikt modeļu saskaņošanu rekursīvā veidā, izmantojot opciju -r, kā parādīts nākamajā piemērā.
Vispirms izveidojiet 2 apakšdirektorijus un kopējiet tajos failu sample.txt:
$ mkdir -p dir1/dir2 $ cp sample.txt dir1/ $ cp sample.txt dir1/dir2/
Tagad veiksim meklēšanas darbību rekursīvā veidā:
$ egrep -r professionals dir1

Iepriekš minētajā piemērā redzams, ka failiem dir1/dir2/sample.txt un dir1/sample.txt parauga atbilstība ir izdevies.
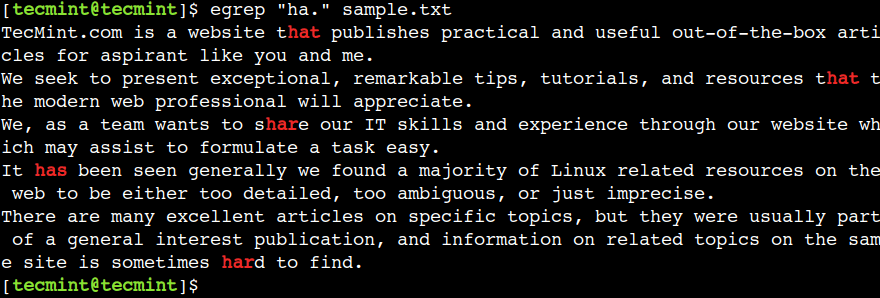
Mēs varam izmantot rakstzīmi (.), lai atbilstu jebkurai rakstzīmei, izņemot rindas beigas. Piemēram, zemāk esošā regulārā izteiksme atbilst tekstam har, hat, un tai ir:
$ egrep "ha." sample.txt
Mēs varam izmantot zvaigznīti (*), lai atbilstu nullei vai vairākiem iepriekšējās rakstzīmes gadījumiem. Piemēram, zemāk esošā regulārā izteiksme atbilst tekstam, kurā ir virkne we, kam seko nulle vai vairāk rakstzīmes b gadījumu.
$ egrep "web*" sample.txt

Mēs varam izmantot pluszīmi (+), lai atbilstu vienam vai vairākiem iepriekšējās rakstzīmes gadījumiem. Piemēram, zemāk esošā regulārā izteiksme atbilst tekstam, kurā ir virkne we, kam seko vismaz viens rakstzīmes b gadījums.
$ egrep "web+" sample.txt
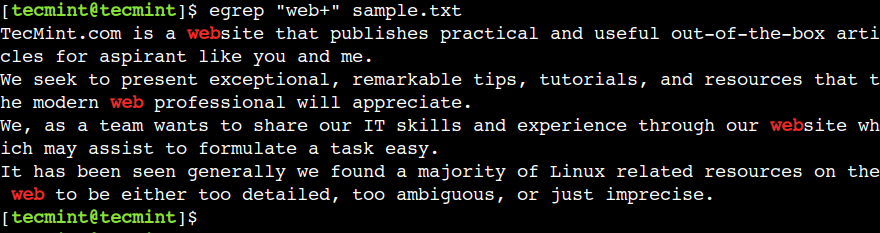
Šeit mēs redzam, ka parauga atbilstības noteikšana neizdodas vārdiem — mēs un bija, jo trūkst rakstzīmes b.
Mēs varam izmantot punktu (^), lai attēlotu rindas sākumu. Piemēram, tālāk norādītā regulārā izteiksme izdrukā rindiņas, kas sākas ar tekstu Mēs:
$ egrep "^We" sample.txt

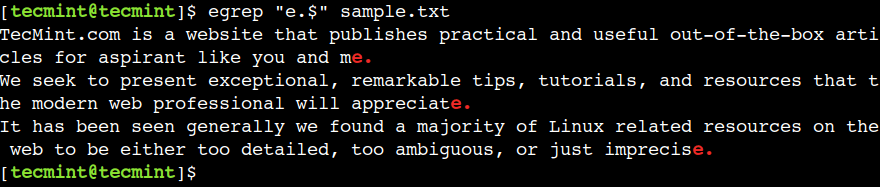
Mēs varam izmantot dolāru ($), lai attēlotu rindas beigas. Piemēram, tālāk norādītā regulārā izteiksme izdrukā rindiņas, kas beidzas ar tekstu e.:
$ egrep "e.$" sample.txt
Mēs varam izmantot punktu (^), kam tūlīt seko dolārs ($), lai attēlotu tukšo rindiņu. Izmantosim to regulārajā izteiksmē, lai noņemtu tukšās rindas:
$ egrep -n -v "^$" sample.txt
Iepriekš redzamajā izvadē redzams, ka rindas numuri 2, 4, 6, 8 un 10 netiek parādīti, jo tie ir tukši.
Šajā rakstā mēs apspriedām dažus noderīgus egrep komandu piemērus. Šos piemērus var izmantot ikdienas dzīvē, lai uzlabotu produktivitāti.
Vai zināt kādu citu labāko komandas egrep piemēru operētājsistēmā Linux? Paziņojiet mums savu viedokli tālāk sniegtajos komentāros.